前回の振り返り
- 制御ステップでは、予約済みリソースに対して初期設定・接続・リアルタイム制御・終了後の解除までを実行
- LSO(ライフサイクルサービスオーケストレーション)により、プリロールからリリースまでの流れを一貫管理
- SDN/BCコントローラーとの連携によって、操作と接続の同期が保たれる
前回は、番組のライフサイクル全体に応じて、制御内容が動的に変化する「LSO」的な運用の重要性について見てきました。
今回は「監視」をテーマに、リアルタイムな状態確認、AIを活用した予兆検知、サービス状態に応じたモニタリングの考え方を紹介します。

監視とは何か?
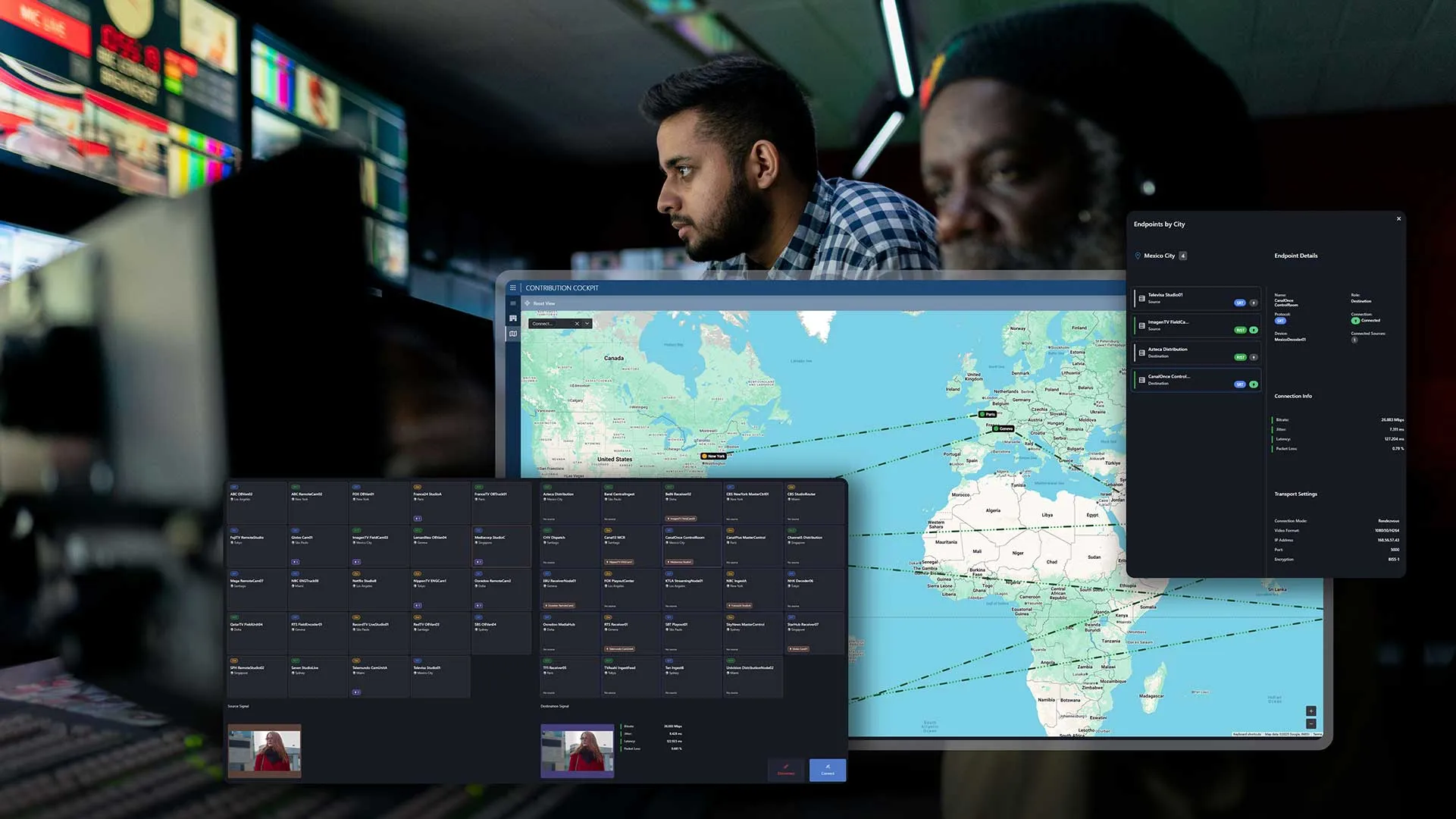
「監視」は単に異常を通知するための仕組みではなく、制作・送出に必要な全リソースとその状態を可視化することが目的です。
- 機器が”使える”状態か、”使っている”状態か
- ネットワークやメディアフローが想定通りに動作しているか
リアクティブ vs プロアクティブな監視
従来はリアクティブ・モニタリング(反応的監視)が主流でしたが、現在ではプロアクティブ・モニタリング(積極的監視)への転換が進んでいます。
| 項目 | リアクティブ(反応的) | プロアクティブ(積極的) |
|---|---|---|
| タイミング | 問題発生後にアラーム | 問題が起きる前に予兆検知 |
| アプローチ | 閾値ベースで通知 | 傾向分析やAI予測 |
| 例 | 温度が上昇しすぎたら通知 | ファン回転数低下から異常を予測 |

監視対象の分類
監視の対象は大きく2つに分けられます:
1.インフラ監視(ノース・サウス方向)
- サーバー、ネットワークスイッチ、ストレージ
- 環境(温度、電力、漏水センサー)
2.メディア監視(イースト・ウェスト方向)
- ストリーム品質(ビットレート、ジッター、遅延)
- ビデオプローブ、マルチビューワー、トランスポートストリームアナライザー
監視項目の更新頻度と手法の最適化
- 状態変化が激しい項目(例:ネットワークリンク)はリアルタイム監視が有効
- 緩やかな変化や非頻繁項目(例:ファームウェア)はポーリング/通知ベースで効率的に対応
サービス意識のある監視
すべてのアラームが常に必要とは限りません。サービスの状態に応じて”正常”と”異常”を判断する必要があります。
- 例1:使用中のビデオサーバーが出力0Mbps → 異常
- 例2:未使用中のビデオサーバーが出力0Mbps → 正常
DataMinerは番組スケジュールや状態と連動して監視テンプレートを切り替えることができます。
トポロジーとサービス依存関係の把握
問題が発生したとき、その影響範囲を即座に特定できることが重要です。
- どの番組/サービスがその機器に依存しているか
- 冗長機器でカバーできるかどうか
- 優先復旧対象はどれか
SDN/BCコントローラーとの統合監視
監視対象はIP機器だけでなく、SDN/ブロードキャストコントローラー自身も含まれます。
- コマンドが発行されたが、実際の信号がルート上に存在しない(=切替失敗)
- 意図しないフローが存在する「ゴーストフロー」の検出
- 重要なアラームはBCコントローラーのUI上でも通知されるよう連携可能
今回のまとめ
- 監視はリアルタイム運用を支えるための情報インフラ
- リアクティブからプロアクティブへと進化しつつある
- 番組状態と連動したアラーム判定=サービス意識型監視が鍵
- インフラとメディアの両面から全体を見渡す必要がある
- SDN/BCとの監視連携によって、信号経路の整合性も保証される
結論と次回予告
監視は「問題がないことを確認する」ためにも欠かせないステップです。
最終回(第6回)では、これまで紹介してきたすべてのステップと機能を統合的に提供できるDataMinerの役割について見ていきます。
製品情報